
Guest Post By Michael Cheeseman, 2020-2021 Sustainability Leadership Fellow and Ph.D. Candidate in the Department of Atmospheric Science at Colorado State University
I love chocolate. Love. It. I think I was brainwashed as a child to enjoy dark chocolate because my parents wanted a healthier alternative to cheesecake, doughnuts, and ice cream. However, I am also a graduate student with a stipend, so I don’t want to spend money on fancy chocolate that I’m not sure I’ll like. What can I do to ensure I spend my money wisely while I try to satiate my addiction?
I could always buy the exact same chocolate, but if I want to try something new, I want to be able to predict that I will like it. One way to do this is to create a predictive model that uses information about the chocolate I’ve already tried in order to guess whether I will like new chocolate. I will use a Random Forest model, a type of machine learning model, which means it teaches itself using data. It sounds complicated but Random Forests actually make a lot of intuitive sense. So let’s get started:
Firstly, we need to begin with our question. In this case: “what chocolate bars do I like and what chocolate bars do I not like?”
Secondly, we need to create a dataset, the lifeblood of all models, that incorporates the characteristics of different chocolate bars that I have previously eaten and either like or don’t like. I created an example dataset below for our purposes:
Cocoa % | Cost $ | Fruit | Caramel | White | Spicy | Nuts | Do I like this bar? | |
 | 30% | 1.00 | N | N | N | N | N | Gross |
 | 62% | 4.00 | Y | N | N | N | N | Yummy |
 | 78% | 4.00 | N | Y | N | N | N | Yummy |
 | 47% | 2.79 | N | N | N | Y | N | Gross |
 | 72% | 3.29 | N | N | N | N | Y | Yummy |
 | 70% | 2.79 | N | N | N | N | N | Yummy |
 | 70% | 9.59 | N | N | N | N | N | Yummy |
 | 0% | 1.00 | N | N | Y | N | N | Gross |
 | 0% | 3.00 | N | N | Y | N | N | Gross |
 | 45% | 4.00 | N | N | N | N | Y | Yummy |
The table above describes the properties of 10 chocolate bars (the more chocolate bars I add to the table, the more information the model will have to make a prediction). The center columns, such as “cocoa percentage” or “nuts”, are what we call predictors. I only show a few predictors here but we can use many predictors. The far right column holds the answer to the question “Do I like this specific chocolate bar?” (in machine learning we would call this the “target” variable). Our Random Forest model will try to find relationships between the predictor variables and the target variable.
So how do we go from this table to creating a model that can predict my fancy chocolate preferences?
To do this imagine that you, the reader, were trying to figure out what chocolate I like and why, but you could only use yes-or-no questions. You may ask a series of questions that look something like this:
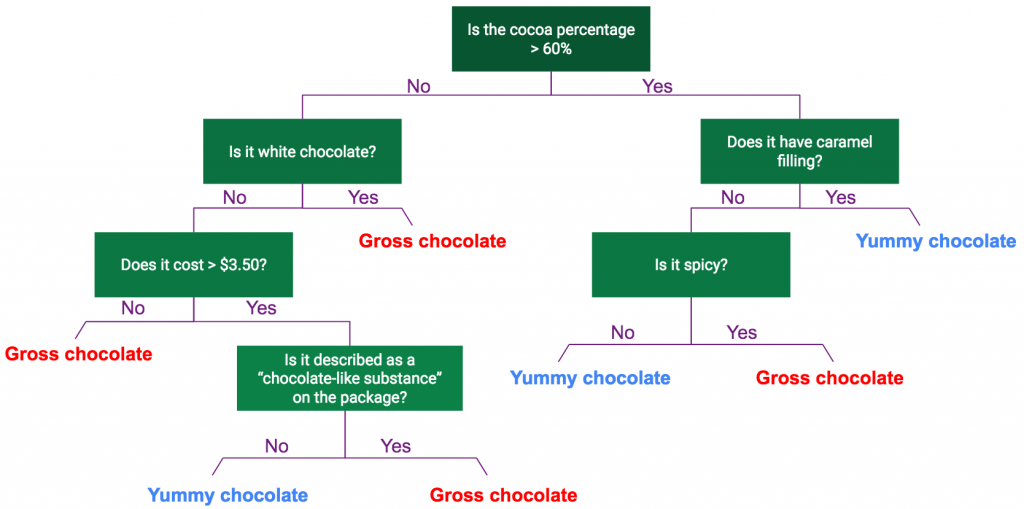
So you’ve asked me a series of questions and I’ve told you whether that chocolate is gross or yummy. Now, do you notice something about the shape of this branching list of questions and answers? It’s kind of in the shape of a tree, right!? We’ve just created what is called a “decision tree”. Decision trees are really easy to interpret because, as we’ve just shown, they mimic a human process of investigation. Notice, however, that we haven’t actually used the decision tree to predict whether I will like new chocolate. Instead, we built this decision tree using information about chocolate I already know. This is called “training our model”. We use a “training dataset” to teach our model to ask the right questions so that it can correctly identify gross and yummy chocolate based on the predictors I have given it. The decision tree above is a very simple example but they can quickly become more complicated, such as the tree below:
A decision tree alone can be a useful tool but what if you chose to ask me totally different questions about these chocolate bars? For example, you could have asked me about its texture or its sweetness level. You might come to a different conclusion about whether or not I like the same chocolate bars. This is why researchers like me use a lot of different decision trees (i.e. a “Forest”), because it is easy for one decision tree to get it wrong but many decision trees that use a variety of predictors and training examples can create a much more reliable prediction. Basically, data science loves a crowd.
Now we know why these models are referred to as a “Forest” but what makes them “Random”?
This is part of the key to their success. If all the decision trees used the exact same questions (i.e. predictors) and the exact same training data (i.e. they learned what chocolate I liked using the exact same group of chocolate bars), then the trees may be very similar to each other and make the same mistakes. So we randomize two aspects of our decision trees to ensure that these models learn about my chocolate tastes in a variety of ways. Firstly, we only give each tree a random subset of our training data. Secondly, each tree only gets to work with a random subset of the predictors. In other words, one decision tree might only get to look at how much the chocolate bars cost, and whether they have fruit or nuts, while another tree may only get to use the cocoa percentage of the chocolate, the cost, and if they are white chocolate or not. This ensures that each tree is sufficiently different from each other, which helps the trees protect each other from their individual errors.
How do we know if our Random Forest can predict my chocolate preferences?
Finally, to recap, we gathered a dataset of 10 chocolate bars and detailed the bars I do and don’t like. We trained a forest of randomized decision trees (i.e. a Random Forest) to predict my chocolate preferences based on our list of predictors. In order to test the skill of our model, we would need to create another dataset of bars that I already know are yummy or gross. This dataset would be called our “testing data”. We would feed this dataset to the Random Forest and ask it to guess which bars I think are yummy or gross. If the model turns out to be really good at guessing which bars from the testing set I like then I can be confident that it could guess whether or not I will like chocolate that I have never tried before! Thus, it could save me money while I strive to satisfy my chocolate cravings.
Great the model can predict my chocolate taste but can we actually learn something about my chocolate tastes that I didn’t already know?
As you can probably guess, the answer is a resounding yes! One useful aspect of machine learning like our Random Forest is that it can recognize patterns in the data that might be hard to pick out with the human eye. Thus, it might tell me things about my taste in chocolate that I never would have known otherwise. For example, I generally do not like cashews in my chocolate but after analyzing the results from the model I might realize that I do like some bars with cashews in them as long as they are paired with fruits or spices. This interpretability is one reason why many researchers in earth science are turning to machine learning methods like Random Forest models: because they can tell us about connections in our world we might not have known otherwise!
Thanks for reading! I’m gonna go eat some more chocolate. Probably this heavenly stuff from Nuance Chocolate made right here in Fort Collins, CO:

References
https://towardsdatascience.com/understanding-random-forest-58381e0602d2
https://www.datacamp.com/community/tutorials/decision-tree-classification-python